大数据是指无法在一定时间范围内使用常规的软件工具进行捕获管理及处理数据的集合。
大数据拥有以下几个特征:
1.大量多样化
2.高速有价值
一、大数据启蒙
分治思想
假如我有n(n很大)个元素(比如数字或单词)需要存储,如果查找一个元素,最简单的遍历方式的复杂度为$O(n)$。
设n=10000,如果期望复杂度为$O(4)$,那该怎么办呢?
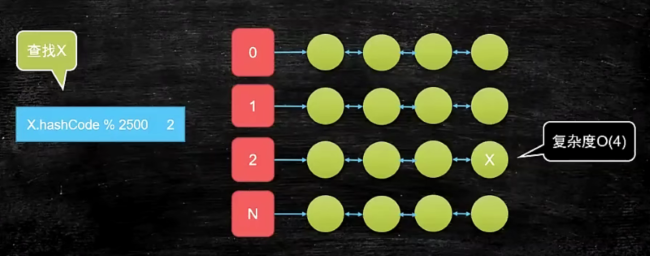
可以利用分治思想,在存储的时候,把数据分成$N(N=n/4)$份,每份存4个元素,得到上图所示的$N$个链(这里的N就为2500)。具体操作就是将元素的哈希值$modN$,得到的结果$result=2$的话,就往第2条链里去存。查找的时候直接在$result$对应的那条链中去找。
单机处理大数据问题
需求:
- 有一个非常大的文本文件,里面有很多很多的行,只有两行一样,它们出现在未知的位置,需要查找到它们。
- 单机,而且可用的内存很少,也就几十兆。
假设IO速度是500MB每秒,1T文件读取一遍需要约30分钟,循环遍历需要N次IO时间。
使用分治思想可以使时间变为2次IO,也就是60分钟左右。

小贴士:内存寻址比IO寻址快10万倍
如果1T文件里存的都是乱序的数字,现在要求对文件里所有数字做一个全排列,那该怎么做呢?哈希这种算法还合适吗?
哈希就不合适了,因为假如数字是3,它的哈希值为9132,这个9132已经影响到了原来数字的数据特征,做不了排序了。
我们可以这样做,每次还是读一行,得到一个数字x,如果(x>0 && x<=100),就把这个数字存到0号文件里,如果(x>100 && x<=200),就把这个数字存到1号文件里,依次类推。这个过程也耗时30分钟左右。这些小文件都是“外部有序,内部无序”的,只要文件够小,就可以直接放到内存中去排个序,按照顺序排好后,依次追加到第一个文件后面。这样总共耗时也就60分钟左右。
这样每次一行一行的读太费劲,而且加入if判断分支过多也会消耗CPU,那还有没有其他方法呢?当然有!
比如我们可以每次读50MB数据,放到内存,在内存中进行排序,生成各个小文件。这些50MB大小的小文件都是“内部有序,外部无序”,这时候我们就联想到归并排序了,数据结构的体现这不就来了!
那如果我们想让时间变为分钟、秒的级别呢?
单机处理的瓶颈就暴露出来了,瓶颈就在IO上,IO速度限制了,并且单机内存也小,内存大的话价格就太贵!
多机处理大数据问题

2000台机器同时启动读取500MB数据(并行计算),耗时1s;每台机器又会从所有机器中并行拉取自己将要计算的500MB数据,假设网卡传输速度为100MB/s,那么拉取500MB就需要5s,我们假设情况比较坏,需要60s;读取到内存判定速度很快,假设为1s。总共就耗时62s。是不是很快?!
但我们是不是忘记了还要将这1T的文件数据分发到2000台机器上去所耗的时间呢?
我们假设网卡传输速度为100MB/s,IO速度又是500MB每秒,读取1T文件又耗时30分钟,所以总共的分发时间就是30*5分钟,也就是将近3个小时。移动数据的成本很高!
这不还没单机处理的速度快吗?! 其实不然~~~
如果考虑每天都有1T的数据产生呢?如果增量了一年,最后一天计算数据呢?(现在不都很流行年度报告嘛)
随着文件的大小越来越大,多机处理的优势就会越来越大!假如文件大小是365T,单机处理得花365个小时,而多机处理仍只需几个小时就能跑完。
结论
- 分而治之
- 并行计算
- 计算向数据移动
- 数据本地化读取
以上这些点都是学习大数据技术时需要关心的重点
二、hadoop-hdfs
分布式文件系统那么多,为什么hadoop项目中还要开发一个hdfs文件系统?
hdfs与其他分布式文件系统有个很大的区别,它能更好的支持分布式计算。
存储模型
- 文件线性按字节切割成块(block),具有offset,id
- 文件与文件的block大小可以不一样
- 一个文件除最后一个block,其他block大小一致
- block的大小依据硬件的IO特性调整
- block被分散存放在集群的节点中,具有location
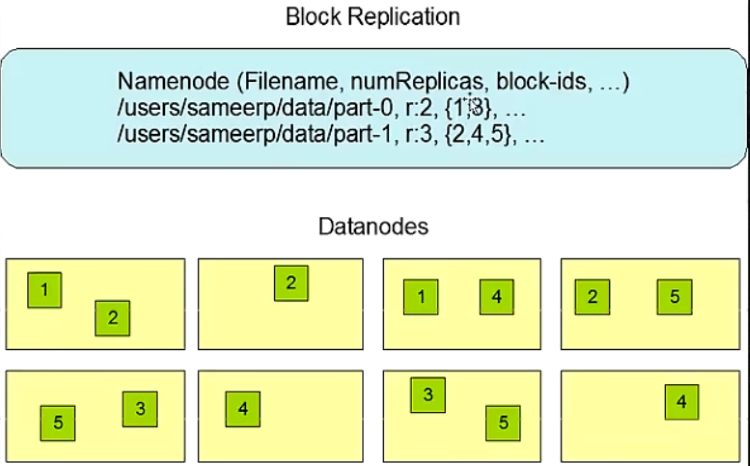
- Block具有副本(replication),没有主从概念,副本不能出现在同一个节点(防止一个节点坏了还可以从其他节点去读取)
- 副本是满足可靠性和性能的关键
- 文件上传可以指定block大小和副本数,上传后只能修改副本数
- 一次写入多次读取,不支持修改(修改是泛红操作)
- 支持追加数据
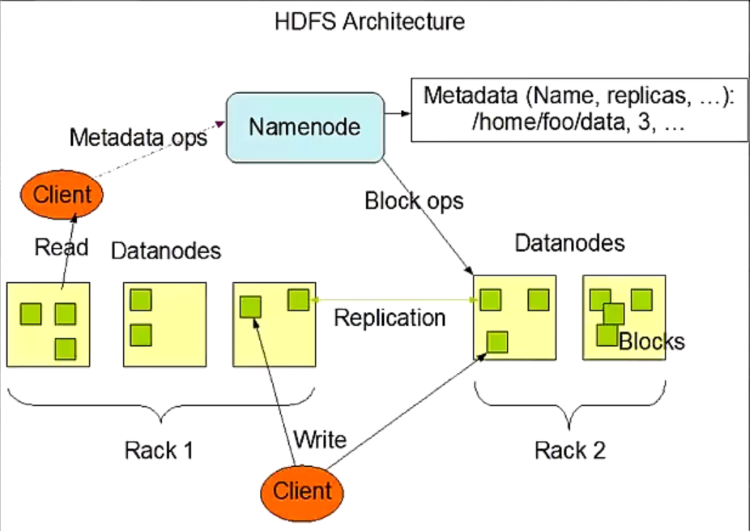
架构设计
- HDFS是一个主从(MasterlSlaves)架构
- 由一个NameNode和一些DataNode组成
- 面向文件包含:文件数据(data)和文件元数据(metadata)
NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
DataNode负责存储文件数据(block块),并提供block的读写
DataNode与NameNode维持心跳,并汇报自己持有的block信息
Client和NameNode交互文件元数据和DataNode交互文件block数据
HDFS架构设计图:
小贴士:角色 即 进程
角色功能
NameNode
- 完全基于内存存储文件元数据、目录结构、文件block的映射
- 需要持久化方案保证数据可靠性(因为内存掉电易失,大小有限)
- 提供副本放置策略
DataNode
- 基于进程所在的操作系统中本地磁盘存储block(以文件的形式)
- 并保存block的校验和数据保证block的可靠性
- 与NameNode保持心跳,汇报block列表状态
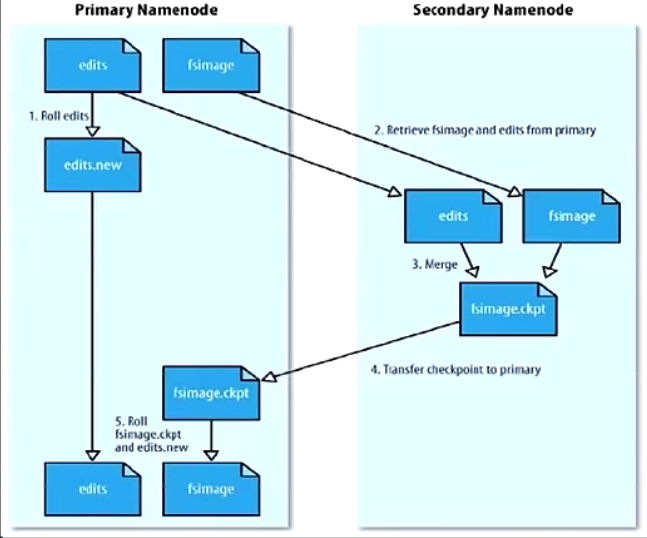
元数据持久化
- 任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来
- 使用Fslmage存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和Fslmage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- Fslmage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了Fslmage+EditLog整合的方案
- 滚动将增量的EditLog更新到Fslmage,以保证更近时点的FsImage和更小的EditLog体积
安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的Fslmage
- 当Namenode启动时,它从硬盘中读取Editlog和Fslmage
- 将所有Editlog中的事务作用在内存中的Fslmage上
- 并将这个新版本的Fslmage从内存中保存到本地磁盘上
- 然后删除旧的Editlog,因为这个旧的Editlog的事务都已经作用在Fslmage上了
- Namenode启动后会进入一个称为安全模式的特殊状态
- 处于安全模式的Namenode是不会进行数据块的复制的
- Namenode从所有的 Datanode接收心跳信号和块状态报告。
- 每当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的。
- 在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态。
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上。
HDFS中的SNN
SecondaryNameNode (SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大值默认是64MB
Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
- 更多副本:随机节点。
HDFS写流程
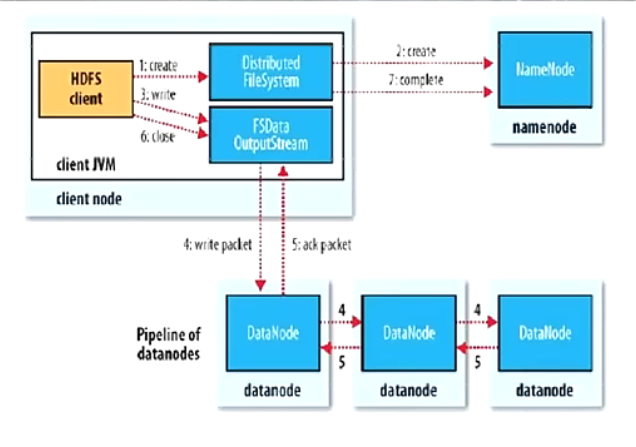
- Client和NN连接创建文件元数据
- NN判定元数据是否有效
- NN处发副本放置策略,返回一个有序的DN列表
- Client和DN建立Pipeline连接
- Client将块切分成packet (64KB),并使用chunk_(512B) +chucksum(4B)填充
- Client将packet放入发送队列dataqueue中,并向第一个DN发送
- 第一个DN收到packet后本地保存并发送给第二个DN
- 第二个DN收到packet后本地保存并发送给第三个DN
- 这一个过程中,上游节点同时发送下一个packet
- 生活中类比工的流水线:结论:流式其实也是变种的并行计算
- Hdfs使用这种传输方式,副本数对于client是透明的
- 当block传输完成,DN们各自向NN汇报,同时client继续传输下一个block
- 所以,client的传输和block的汇报也是并行的
HDFS读流程
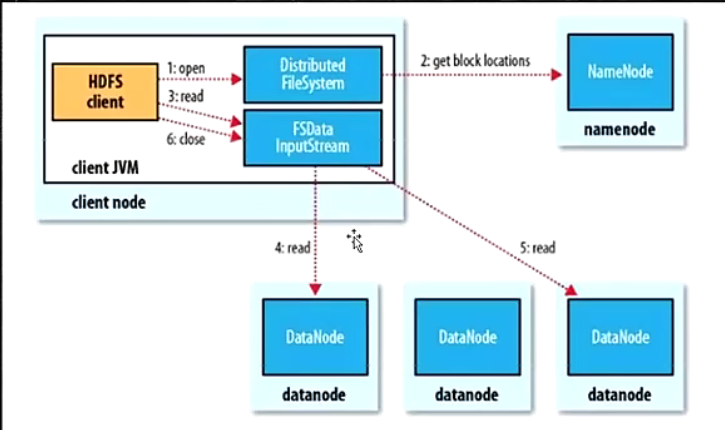
- 为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本
- 如果在读取程序的同一个机架上有一个副本,那么就读取该副本
- 如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本
- 语义:下载一个文件:
- Client和NN交互文件元数据获取fileBlockLocation
- NN会按距离策略排序返回
- Client尝试下载block并校验数据完整性
- 语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
- Hdfs支持client给出文件的offset自定义连接哪些block的DN,自定义获取数据
- 这个是支持计算层的分治、并行计算的核心(需要文件的哪个位置的数据就直接读对应的那一块Block)
