1
2
3
4
5
6
7
8
9
10
|
URL='https://www.sogou.com/'
response=requests.get(url=URL)
page_text=response.text
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
|
- 实现一个简易的网页采集器
- 基于搜狗针对不同的关键字将其对应的页面数据进行爬取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| keyword=input('enter a ketword:')
params={
'query':keyword
}
URL='https://www.sogou.com/web'
reponse=requests.get(url=URL,params=params)
response.encoding='utf-8'
page_text=response.text
fileName=keyword+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileNmae,'爬取完毕!')
|
enter a ketword:jay
jay.html 爬取完毕!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| keyword=input('enter a ketword:')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
params={
'query':keyword
}
URL='https://www.sogou.com/web'
response=requests.get(url=URL,params=params,headers=headers)
response.encoding='utf-8'
page_text=response.text
fileName=keyword+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileNmae,'爬取完毕!')
|
enter a ketword:jay
jay.html 爬取完毕!
爬取豆瓣电影中的电影详情数据
如何捕获动态加载数据
- 基于抓包工具进行全局搜索
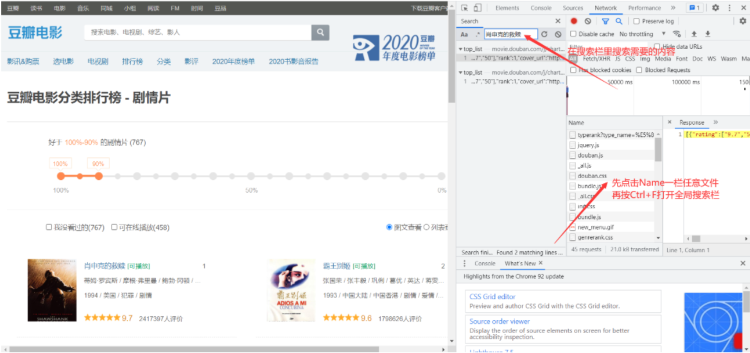
- 定位到动态加载数据对应的数据包,从该数据包中就可以提取出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| URL='https://movie.douban.com/j/chart/top_list'
params={
'type': '11',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20',
}
response=requests.get(url=URL,params=params,headers=headers)
page_text=response.json()
for movie in page_text:
name=movie['title']
date=movie['release_date']
score=movie['score']
print(name,date,score)
|
肖申克的救赎 1994-09-10 9.7
霸王别姬 1993-07-26 9.6
美丽人生 2020-01-03 9.6
控方证人 1957-12-17 9.6
伊丽莎白 2005-12-05 9.6
阿甘正传 1994-06-23 9.5
辛德勒的名单 1993-11-30 9.5
背靠背,脸对脸 1994-09-10 9.5
茶馆 1982 9.5
控方证人 1982-12-04 9.5
十二怒汉(电视版) 1954-09-20 9.5
这个杀手不太冷 1994-09-14 9.4
千与千寻 2019-06-21 9.4
泰坦尼克号 1998-04-03 9.4
忠犬八公的故事 2009-06-13 9.4
十二怒汉 1957-04-13 9.4
泰坦尼克号 3D版 2012-04-10 9.4
灿烂人生 2003-06-22 9.4
横空出世 1999-12-12 9.4
高山下的花环 1985-11-07 9.4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
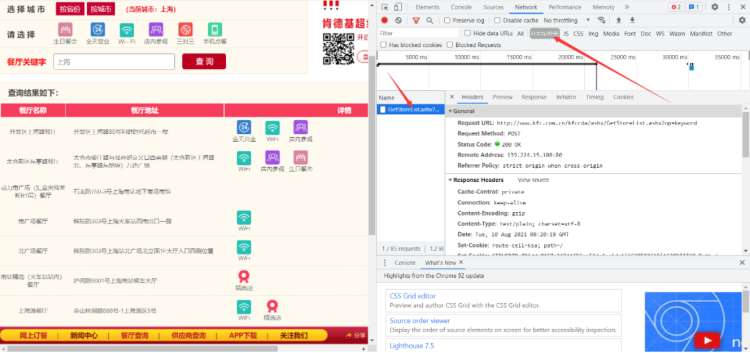
| URL='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1,9):
data={
'cname': '',
'pid': '',
'keyword': '上海',
'pageIndex': str(page),
'pageSize': '10',
}
response=requests.post(url=URL,headers=headers,data=data)
page_text=response.json()
for dic in page_text['Table1']:
storeName=dic['storeName']
addr=dic['addressDetail']
print(storeName,addr)
|
开发区上海路 开发区上海路80号利群时代超市一楼
太仓新区东亭路 太仓市娄江路与县府街交叉口西南侧(太仓新区上海路北、东亭路东地块)万达广场
动力南广场(汇金奥特莱斯B1层) 石龙路750-3号上海南站地下商场南馆
南广场 秣陵路303号上海火车站西南出口一侧
北广场 秣陵路303号上海站北广场北立面1F大厅入口西侧位置
南站精选(火车站站内) 沪闵路9001号上海南站候车大厅
上海滩 佘山林湖路888号-1上海滩区5号
动力南精选(3号线2号出口) 沪闵路9001号上海南站(1F三角地A-1)一层
上海南路 青山湖区上海路3号
亦庄上海沙龙 经济技术开发区天宝园五里二区A1+A2户一层
三和 8100425-沂蒙路与上海路交汇处颐高上海街一期铺位258、259号两层
上海城84832861 人民西路93号1、2层
沭阳大润发 上海南路与苏州西路交汇处
上海路 上海路四段二号
上海四平 杨浦区四平路903号肯德基
上海乳山餐厅 乳山路136号
新客站 秣陵路303号上海站南广场站内一层过安检电梯口旁
上海城 南坪西路上海城一层
江镇 上海浦东新区机场镇晨阳路196号
财富中心 上海路与和平街交叉口大润发商业广场一楼肯德基
新南广 秣陵路303号上海火车站东南出口东侧一层
高铁北精选 铁路上海虹桥站出发层商铺号:3F-A3-1
新上海路 上海北路230号肯德基
南通世茂 新东路101号地块(上海东路北、新河东路东)世茂广场大润发超市内
国展 盈港东路158号国家会展中心(上海)之商业广场一层D-L114号、二层D-L220号 39883261
爱建卓展 上海街99号卓展购物中心二期
金光中心 东长治路588号上海白玉兰广场商场LG2—M55
莱西乐好 青岛路东上海路南莱西乐好时代城一层
中央广场 人民中路与上海中路交叉口的沭阳中央广场一层
宿迁高铁站 三棵树街道富康大道与上海路交叉口东宿迁高铁站候车大厅2层
启东碧桂街区 开发区中邦上海城商业一期13幢一层139室、140室、141室
长兴服务区(南) G50高速长兴服务南区(上海江苏方向)
启东凤凰荟 开发区中邦上海城商业二期购物中心一层1-004号
万象城甜品站 吴中路1599号的上海万象城项目L437b号商铺
中环大厦 中国上海路与民族街十字东北角中环大厦1层
万象城甜品站 吴中路1599号的上海万象城项目L437b号商铺
德清服务区南餐厅(上海方向) 浙江申嘉湖杭高速公路德清服务区南区(上海方向)
启东凤凰荟 开发区中邦上海城商业二期购物中心一层1-004号
中环大厦 中国上海路与民族街十字东北角中环大厦1层
佘山宝地 上海佘月路27号一 层 105+107 号
新化恒太城 上海路东方城市广场1层
新化恒太城 上海路东方城市广场1层
佘山宝地 上海佘月路27号一 层 105+107 号
德清服务区南餐厅(上海方向) 浙江申嘉湖杭高速公路德清服务区南区(上海方向)
爱建卓展甜品站 上海路99号
爱建卓展甜品站 上海路99号
爱建卓展甜品站 上海路99号
爱建卓展甜品站 上海路99号
上海路 二堰街办上海路58号1幢1-5书香嘉苑一层
上海路 二堰街办上海路58号1幢1-5书香嘉苑一层
新沂吾悦 上海路与大桥路交叉口新城吾悦广场【1001-1】号商铺
新沂吾悦 上海路与大桥路交叉口新城吾悦广场【1001-1】号商铺
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| URL1='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
id=[]
for page in range(1,6):
data={
'on': 'true',
'page': str(page),
'pageSize': '15',
'productName': '',
'conditionType': 1,
'applyname': '',
'applysn': '',
}
response=requests.post(url=URL1,data=data,headers=headers)
page_text=response.json()
for eps in page_text['list']:
id.append(eps['ID'])
URL2='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
fileName='化妆品企业.txt';
with open(fileName,'a',encoding='utf-8') as fp:
for i in range(75):
data={
'id': id[i]
}
response=requests.post(url=URL2,data=data,headers=headers)
page_text=response.json()
epsName=page_text['epsName']
certStr=page_text['certStr']
epsProductAddress=page_text['epsProductAddress']
legalPerson=page_text['legalPerson']
fp.write('企业名称:'+epsName+' 许可项目:'+certStr+' 生产地址:'+epsProductAddress+' 法定代表人:'+legalPerson+'\n')
print(fileName,'爬取完毕!')
|
化妆品企业.txt 爬取完毕!
![]()
感谢鼓励